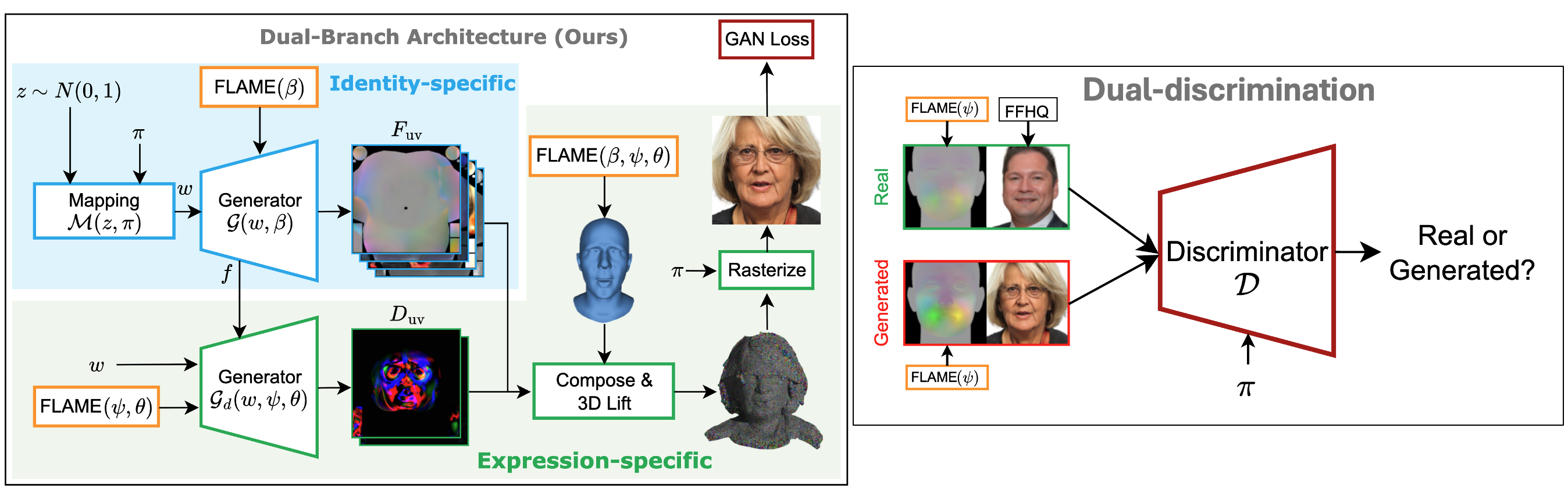
AGORA builds upon the UV-based GGHEAD framework, extending it into a fully animatable 3D GAN. The generator produces canonical 3DGS attributes — position, scale, rotation, color, opacity — in UV space from a latent code and FLAME shape parameters. A separate lightweight deformation branch takes low-resolution feature maps from the main generator and predicts per-Gaussian attribute residuals conditioned on FLAME expression ψ and jaw pose θ, which are composed with the canonical attributes to produce the final animated avatar. Gaussian positions are obtained by 3D lifting: interpolating base positions from the articulated FLAME mesh and adding predicted offsets, anchoring the 3DGS to the parametric mesh geometry.
Spatial Shape Conditioning
A key challenge in animatable generation is injecting shape priors (e.g., craniofacial proportions) without collapsing identity diversity. Naively injecting the FLAME shape code β into the mapping network causes the intermediate latent to be dominated by β, suppressing z-driven variation. Instead, we derive a UV-aligned map of the shape-isolated deformation field — the difference between a posed FLAME mesh with a given shape and a canonical reference — apply per-sample variance normalization, and concatenate it with the generator's block features. This injects shape biases spatially, where they matter geometrically, while preserving the stochasticity of the latent code.
Enforcing Expression Consistency
Training with only an image-based discriminator is insufficient for precise expression control. Following Next3D, we condition the discriminator on the target expression by concatenating the rendered image with a synthetic FLAME mesh rendering. Crucially, we replace UV-coordinate vertex coloring with a displacement-based signal: vertices are colored by their expression-isolated displacement from the neutral pose, giving the discriminator a fine-grained geometric cue to penalize expression deviations. This dual-discrimination scheme significantly improves mouth articulation and high-intensity expression fidelity.
AGORA-M: Mobile Gaussian Blendshapes
Running the full generation network per frame is too expensive for mobile deployment. We propose AGORA-M: an offline step samples N tuples from the trained model, computes posed-minus-neutral Gaussian attribute residuals, and factorizes them via SVD to obtain K shared Gaussian blendshapes. At runtime, a lightweight two-layer MLP regresses blendshape coefficients from FLAME parameters, and the final avatar is a linear combination of the neutral avatar and the blendshapes. Identity precomputation runs once; expression replay costs only the MLP forward pass and one linear blend — achieving 560 FPS on a single GPU and 60 FPS on mobile phones with minimal quality trade-off.